People

Jim Glass
PI - MIT

Hilde Kuehne
PI - IBM

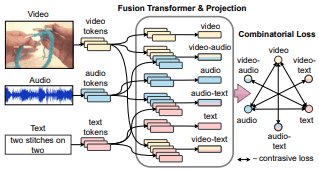
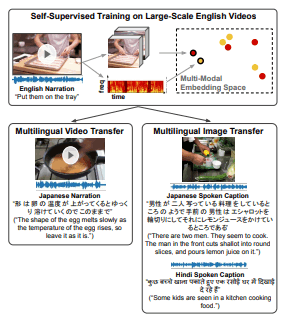
The sight and sound project focuses on the training and recognition of multi-modal data. We target feature representations and higher level semantic concepts by training neural networks with multi-modal data such as videos, sounds, and texts.










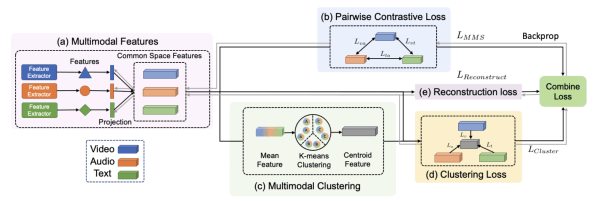
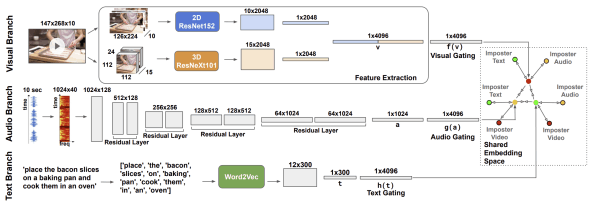
AVLnet: Learning Audio-Visual Language Representations from Instructional Videos
Andrew Rouditchenko, Angie Boggust, David Harwath, Brian Chen, Dhiraj Joshi, Samuel Thomas, Kartik Audhkhasi, Hilde Kuehne, Rameswar Panda, Rogerio Feris, Brian Kingsbury, Michael Picheny, Antonio Torralba, James Glass; Interspeech 2021
Paper , Code
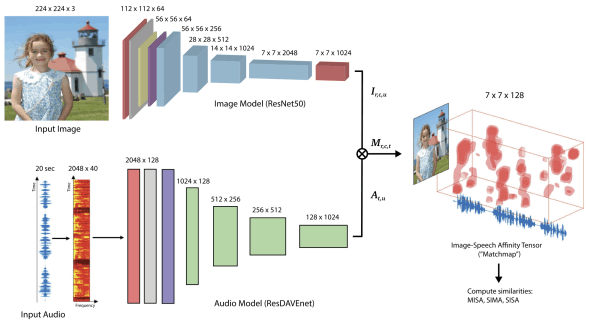
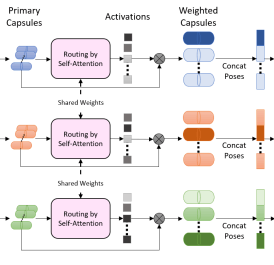
Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input
David Harwath, Adrià Recasens, Dídac Surís, Galen Chuang, Antonio Torralba, James Glass; IJCV 2020
Paper